Video annotation, the process of labeling video data, is the secret behind intelligent computer vision. Imagine teaching a computer to “see” by adding labels to objects, actions, and scenes in videos. This labeled data trains AI models to perform tasks like self-driving car navigation, medical diagnostics, and even creating realistic virtual worlds. While challenges like data volume and accuracy control exist, the future is bright. Automation, collaboration tools, and AI integration are poised to make video annotation faster, more efficient, and instrumental in shaping the future of AI.

What is Video Annotation
Introduction to Video Annotation
Video annotation, also referred to as video labeling, is the process of adding labels and descriptions to video footage. This is specifically done to train computer vision models, a type of artificial intelligence (AI) responsible for identifying and understanding visual information in videos. Annotations act like guideposts, helping the AI make sense of the visual data and learn to recognize objects, actions, or even emotions within the video.
Importance of Video Annotation
Video annotation plays a crucial role in the development of accurate and powerful computer vision models. Here’s why it’s important:
- Training AI Systems: Annotated videos provide the foundation for training AI models. The labels act as ground truth, allowing the AI to learn the correct way to identify objects and patterns in new videos.
- Accurate Object Detection: High-quality annotations ensure that AI models can accurately detect and recognize objects in videos with minimal errors. This is essential for applications like self-driving cars, security systems, and robotics.
- Improved Action Recognition: Annotations can be used to train AI models to recognize specific actions happening in videos. This is useful in applications like video surveillance or analyzing sports footage.
- Advanced Video Analysis: Detailed annotations allow for in-depth analysis of videos, enabling AI to understand complex scenes and identify subtle details.
Overall, video annotation is a critical step in unlocking the potential of computer vision. By providing high-quality labeled data, we can train AI models to perform a wide range of tasks, ultimately leading to smarter and more capable machines.
Best Practices for Effective Video Annotation
Here are some key practices to ensure accurate and efficient video annotation, along with illustrative examples:
1. Choosing the Right Annotation Technique:
- Image: Use this for tasks requiring individual frame labeling, like object identification in a single image.
- Video: This is suitable for labeling objects with movement across frames.
2. Leverage Keyframes and Interpolation:
- View the entire video first to identify keyframes – representative frames that capture significant changes.
- Annotate keyframes, then use interpolation tools within the annotation software to automatically label in-between frames with consistent movement, saving time.
3. Standardize Annotation Guidelines:
- Create a clear guide defining what objects to label, annotation tools to use, and handling occlusions (when objects are hidden).
- This ensures consistency among annotators and reduces errors.
4. Utilize Quality Assurance:
- Implement a multi-stage review process to check for annotation mistakes.
- This can involve senior annotators reviewing work or using automated validation tools.
5. Leverage Automation When Possible:
- Explore video annotation software with features like auto-annotation, which suggests labels based on previous annotations, speeding up the process.
6. Prioritize High-Quality Video:
- The quality of the video footage significantly impacts annotation accuracy.
- Ensure good lighting, resolution, and minimal blur for easier object identification.
7. Train and Calibrate Annotators:
- Provide training on the annotation task, specific labeling guidelines, and the annotation software.
- Regularly calibrate annotator performance to maintain consistency.
By following these best practices, you can achieve high-quality video annotations that effectively train your computer vision models and unlock their full potential.
Types of Video Annotation
Video annotation utilizes various techniques to label specific elements within a video frame. Here’s a breakdown of common types with visuals:
1. Bounding Boxes:

- Description: This is the most common method. Annotators draw rectangular boxes around objects of interest in each frame.
- Example: A security video where a bounding box is drawn around a person walking through a doorway.
2. Polygon Annotation:
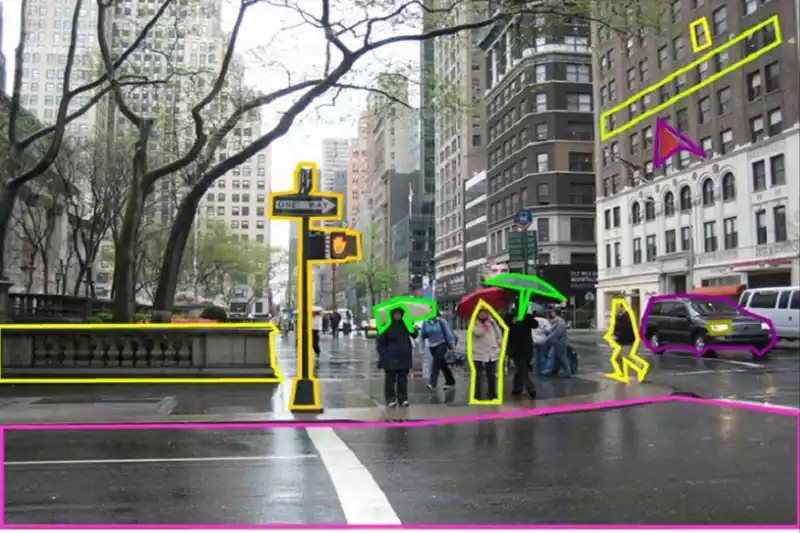
- Description: Used for objects with irregular shapes or those that change shape during movement. Annotators create closed shapes using multiple points to precisely outline the object.
- Example: Annotating a bird in flight. A polygon would more accurately capture the bird’s wings than a bounding box.
3. Semantic Segmentation:
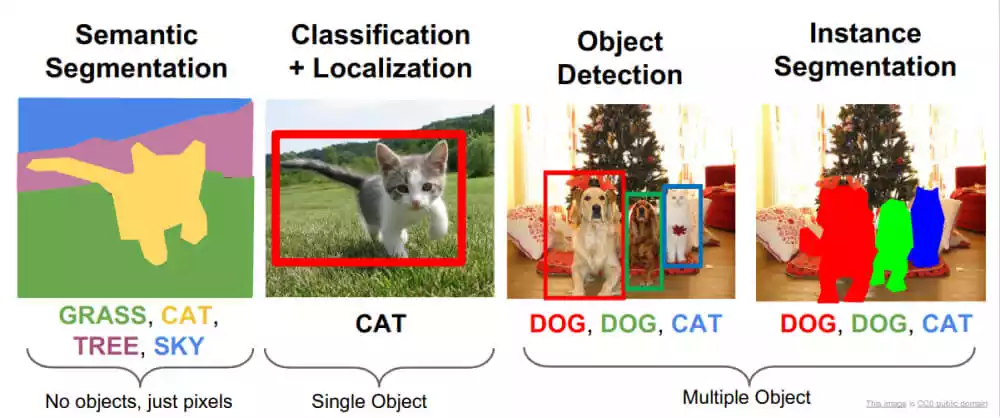
- Description: This method goes beyond outlining objects. Each pixel in a frame is labeled to identify specific objects or areas within the scene.
- Example: Segmenting a traffic scene, where each pixel is labeled as “car,” “road,” “sidewalk,” etc.
4. Keypoint Annotation:
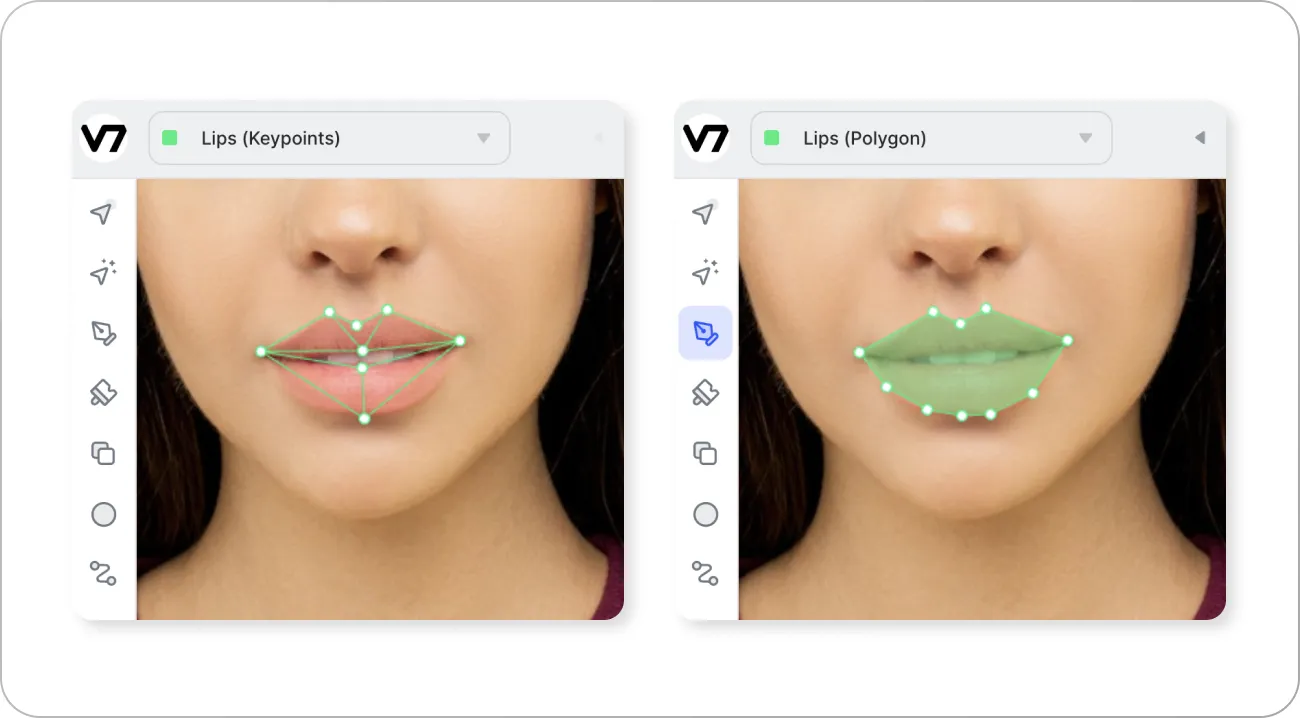
- Description: This approach focuses on labeling specific points on an object, typically used for tracking pose, movement, or facial features.
- Example: Annotating facial keypoints like eyes, nose, and mouth to track a person’s expressions in a video.
5. 3D Cuboid Annotation:
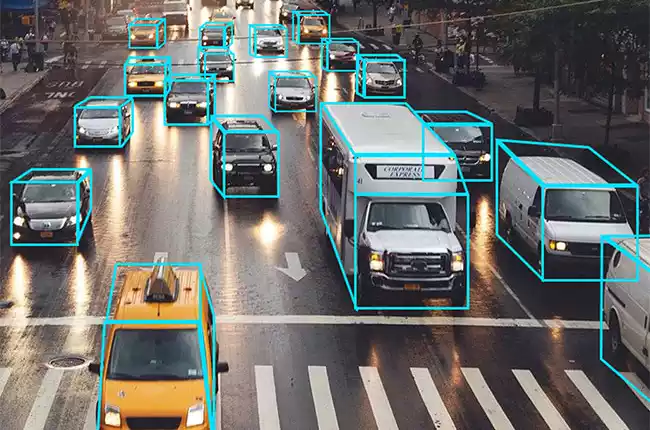
- Description: This method adds a depth dimension to bounding boxes. Annotators create 3D boxes around objects to capture their position and orientation in space.
- Example: Annotating furniture in a virtual reality (VR) environment. Cuboids provide a more accurate representation of the furniture’s size and position.
6. Activity Recognition:
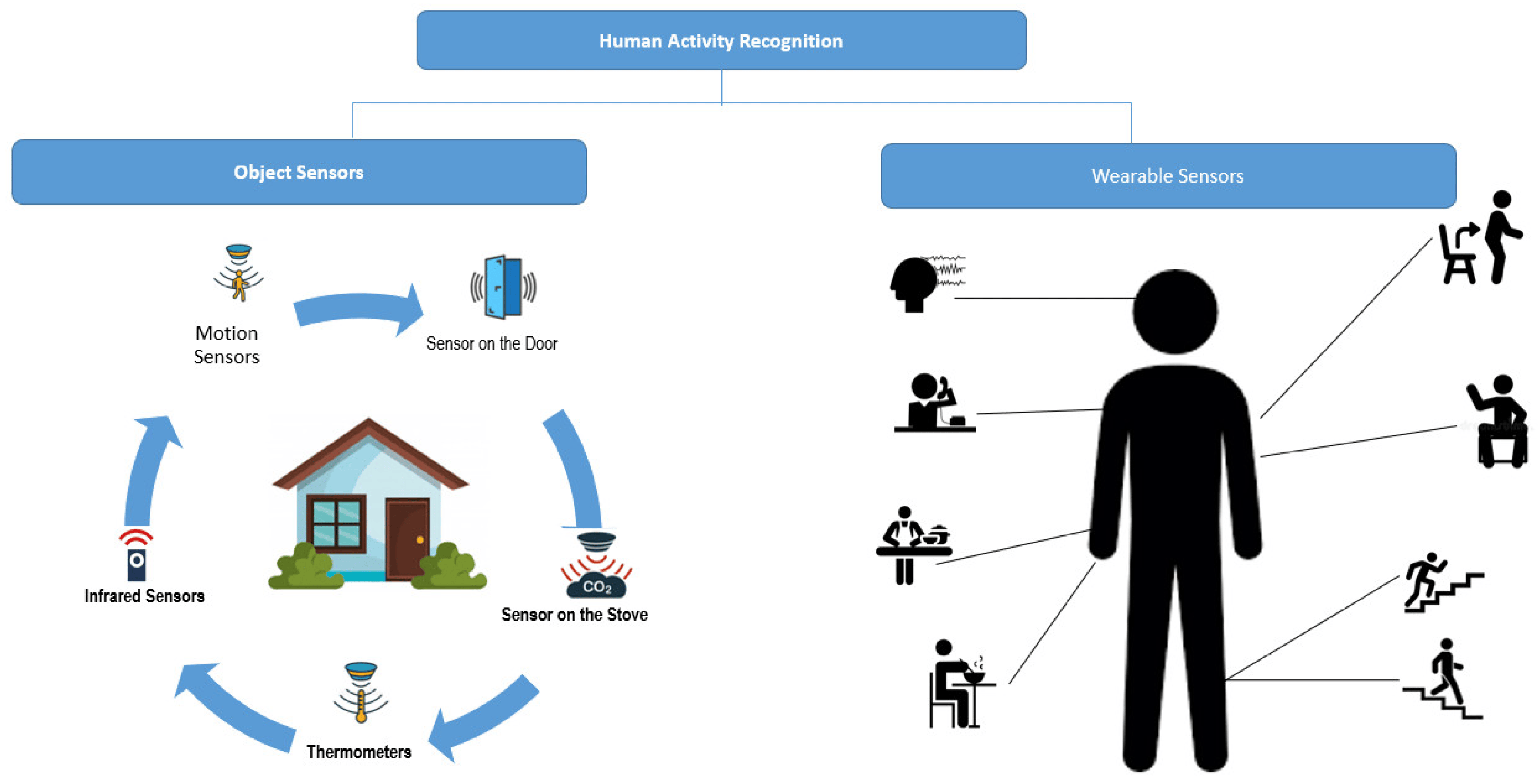
- Description: This technique goes beyond object labeling. Annotators define and label specific actions occurring within the video.
- Example: Annotating a sports video, labeling actions like “shooting a basketball” or “making a tackle” in football.
The choice of annotation type depends on the specific task and the level of detail required for your computer vision model.
How Video Annotation Works
Video annotation, also known as video labeling, is the process of adding labels and descriptions to video data. This enriched data is used to train computer vision models, a type of artificial intelligence (AI) that can “see” and understand the visual world. Here’s a breakdown of how video annotation works:
1. Define the Goal and Data Collection:
- The first step involves defining the purpose of the video annotation project. What do you want your AI model to be able to do? This could be object detection (identifying cars in a video), activity recognition (spotting people walking in a security camera feed), or something more complex.
- Once the goal is clear, relevant video data is collected. This might involve recording new footage, gathering existing videos, or a combination of both.
2. Choosing the Annotation Technique:
Different annotation techniques are suited for different tasks. Common methods include:
- Bounding Boxes: Drawing rectangles around objects of interest (e.g., marking cars in traffic footage).
- Polygons: Creating more complex shapes for irregular objects (e.g., outlining a person riding a bike).
- Semantic Segmentation: Labeling every pixel in a frame to identify specific objects (e.g., differentiating cars, pedestrians, and roads in a scene).
The choice of technique depends on the level of detail needed and the specific objects or actions you want the model to recognize.
3. The Annotation Process:
Video annotation platforms are used to streamline the labeling process. These platforms allow users to:
- View and navigate video frames.
- Use annotation tools to draw bounding boxes, polygons, or other labels on the frames.
- Add detailed descriptions or classifications to the labels (e.g., specifying the type of car or the person’s activity).
Often, a quality assurance process is implemented to ensure accuracy. This might involve senior annotators reviewing work or using automated validation tools to catch inconsistencies.
4. Training the AI Model:
- Once a significant amount of video data is annotated, it’s used to train the computer vision model. The annotated data acts as a reference point, showing the model the correct way to identify objects, actions, or patterns within new, unseen videos.
- As the model is trained on this labeled data, it learns to recognize the patterns and relationships between pixels in the video. This allows it to perform the task you defined in step 1, like object detection or activity recognition.
5. Refining and Improvement:
- The training process is often iterative. After the initial training, the model’s performance is evaluated on new, unlabeled videos. If the results aren’t ideal, the model might be retrained with additional annotated data or adjustments might be made to the annotation process itself.
By following these steps, video annotation helps bridge the gap between raw video data and powerful AI models that can interpret and understand the visual world.
Applications of Video Annotation
Video annotation plays a crucial role in various fields by enabling the development of intelligent computer vision systems. Here are some key applications with illustrative examples:
1. Self-Driving Cars:

- Description: Video annotation is essential for training AI models that power self-driving cars.
- Example: Annotators meticulously label objects like cars, pedestrians, traffic lights, and lane markings within video footage. This data helps the car’s AI model distinguish these elements, navigate roads safely, and make real-time decisions while driving.
2. Advanced Security Systems:
- Description: Video annotation empowers security systems with advanced object detection and activity recognition capabilities.
- Example: Security camera footage can be annotated to identify people entering restricted areas, objects being left unattended, or suspicious activities taking place. This empowers security personnel to respond quickly and effectively to potential threats.
3. Sports Analytics and Performance Analysis:

- Description: Annotated video data is used to train AI models for analyzing sports footage.
- Example: In sports like football, annotating player movements and actions allows coaches to gain insights into player performance, identify areas for improvement, and develop effective strategies.
4. Medical Diagnosis and Research:
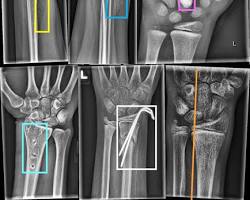
- Description: The medical field is increasingly leveraging video annotation for tasks like analyzing medical scans and automating diagnostics.
- Example: In radiology, X-rays or MRI scans can be annotated to identify tumors, fractures, or other abnormalities. This aids radiologists in early and accurate diagnoses.
5. Content Moderation and Video Recommendation:
- Description: Social media platforms and video streaming services use video annotation to filter inappropriate content and personalize recommendations.
- Example: Annotating videos can help identify violent content, hate speech, or age-restricted material, allowing platforms to moderate content effectively. Additionally, video annotation can be used to identify objects or actions within videos, enabling platforms to recommend similar content based on user preferences.
6. Virtual Reality (VR) and Augmented Reality (AR):
- Description: Video annotation plays a role in creating realistic and interactive VR/AR experiences.
- Example: 3D object annotation can be used to define the size, position, and orientation of virtual objects within a VR environment. This allows for accurate and immersive experiences.
These are just a few examples of how video annotation is transforming various industries. As computer vision technology continues to evolve, we can expect even more innovative applications of video annotation to emerge in the future.
Challenges and Future Trends in Video Annotation
Challenges in Video Annotation
While video annotation is a powerful tool, it’s not without its challenges. Here are some key obstacles to consider:
- Data Volume and Scalability: Training robust AI models often requires vast amounts of labeled video data. Collecting, storing, and annotating this data can be time-consuming, expensive, and require significant storage and processing resources.
- Accuracy and Consistency: High-quality annotations are crucial for training accurate AI models. However, ensuring consistency among annotators and maintaining labeling accuracy across large datasets can be challenging.
- Privacy Concerns: Video data often contains personal information, raising privacy concerns. Balancing the need for effective annotation with ethical data handling practices is essential.
- Complexity of Annotation Tasks: Annotating complex scenes with intricate details, occlusions (hidden objects), or fast-moving objects can be time-consuming and require specialized skills from annotators.
- Cost and Resource Constraints: The process of video annotation can be labor-intensive, requiring a skilled workforce or specialized annotation tools. This can lead to high project costs, especially for large-scale annotation tasks.
Future Trends in Video Annotation
Despite the challenges, the field of video annotation is constantly evolving. Here are some exciting trends to look forward to:
- Automation and AI-Assisted Annotation: The use of artificial intelligence (AI) to automate repetitive tasks within the annotation process is gaining traction. AI can help with tasks like pre-labeling objects, suggesting labels based on previous annotations, and streamlining the workflow.
- Active Learning and Semi-Supervised Learning: These machine learning techniques can help reduce the amount of manually labeled data needed. Active learning prioritizes the most informative videos for annotation, while semi-supervised learning leverages both labeled and unlabeled data for training.
- Focus on Collaborative Annotation Platforms: Cloud-based annotation platforms with real-time collaboration features will become more prevalent. This allows geographically dispersed teams to work together on video annotation projects efficiently.
- Standardization of Annotation Practices: Developing standardized annotation guidelines and tools will ensure consistency and improve the overall quality of labeled data.
- Integration with Advanced Computer Vision Models: Video annotation tools will likely integrate more seamlessly with advanced computer vision models. This will allow for real-time feedback on annotation quality and continuous improvement of the annotation process.
By addressing the challenges and embracing these future trends, video annotation will continue to play a vital role in unlocking the full potential of computer vision and artificial intelligence.
Conclusion
Video annotation has emerged as a critical tool in the development of powerful computer vision models. By enriching video data with labels and descriptions, we can train AI systems to “see” and understand the visual world. This annotated data serves as the foundation for various applications, from self-driving cars and advanced security systems to medical diagnosis and virtual reality experiences.
While challenges like data management, accuracy control, and project costs exist, the future of video annotation is promising. Advancements in automation, collaborative platforms, and integration with AI models hold the potential to streamline the process and unlock even more innovative applications. As computer vision continues to evolve, video annotation will remain a cornerstone in building intelligent systems that can perceive and interact with the world around us.
FAQs
Q. What are the key differences between manual and automatic video annotation?
A. Manual annotation involves human annotators labeling videos manually, ensuring high accuracy but requiring significant time and effort. In contrast, automatic annotation uses computer algorithms to label videos automatically, offering speed but potentially lower accuracy, especially in complex scenes.
Q. How can video annotation benefit educational institutions?
A. Video annotation allows educators to create interactive learning experiences by adding quizzes, explanations, or additional resources directly within instructional videos. This enhances student engagement and comprehension.
Q. What are the main challenges associated with video annotation?
A. Some of the main challenges include ensuring annotation accuracy, managing the time-consuming nature of manual annotation processes, and addressing the cost implications of large-scale annotation efforts.
Q. What role does video annotation play in machine learning applications?
A. Video annotation provides labeled datasets for training machine learning algorithms, enabling tasks such as object recognition, activity recognition, and sentiment analysis. These annotated datasets are essential for the development and evaluation of machine learning models.
Q. What are some future trends in video annotation technology?
A. Future trends in video annotation include advancements in AI-powered annotation techniques, integration of multi-modal annotations, and real-time annotation capabilities, offering more efficient and interactive annotation experiences.
Data Annotation Jobs | Shaping the Future of Machine Learning in 21st Century
Understanding Data Annotation | Enhancing Machine Learning with Quality Data in 21st Century
How Audio Annotation Makes AI Hear You | Unveiling the Secrets of Sound in 2024
Why Image Annotation Matters Now | Labeling the Future With 04 Types of Image
How Text Annotation Tames the Wild World of Language | The Secret Weapon of AI in 2024
You have to wait 30 seconds.
I truly admired the work you’ve put in here. The design is refined, your authored material stylish, however, you seem to have acquired some trepidation about what you intend to present next. Undoubtedly, I’ll revisit more regularly, similar to I have nearly all the time, in the event you sustain this rise.
I truly enjoyed what you’ve achieved here. The design is stylish, your written content fashionable, yet you appear to have acquired some apprehension regarding what you intend to present going forward. Undoubtedly, I’ll return more frequently, similar to I have almost constantly, in the event you sustain this ascent.
I truly relished the effort you’ve put in here. The sketch is stylish, your authored material chic, however, you seem to have developed some anxiety about what you intend to deliver subsequently. Assuredly, I will revisit more regularly, akin to I have nearly all the time, in the event you maintain this rise.
I sincerely enjoyed what you have produced here. The design is refined, your authored material trendy, yet you appear to have obtained a degree of apprehension regarding what you aim to offer next. Certainly, I shall return more frequently, just as I have been doing almost constantly, provided you uphold this incline.
I sincerely appreciated the effort you’ve invested here. The sketch is tasteful, your authored material chic, however, you seem to have developed some uneasiness about what you aim to offer henceforth. Certainly, I shall revisit more regularly, just as I have been doing nearly all the time, should you uphold this climb.
I truly admired the work you’ve put in here. The design is refined, your authored material stylish, however, you seem to have acquired some trepidation about what you intend to present next. Undoubtedly, I’ll revisit more regularly, similar to I have nearly all the time, in the event you sustain this rise.
I really enjoyed what you have accomplished here. The outline is elegant, your written content is stylish, yet you seem to have acquired a bit of apprehension over what you aim to convey next. Undoubtedly, I will revisit more frequently, just as I have been doing nearly all the time in case you sustain this upswing.