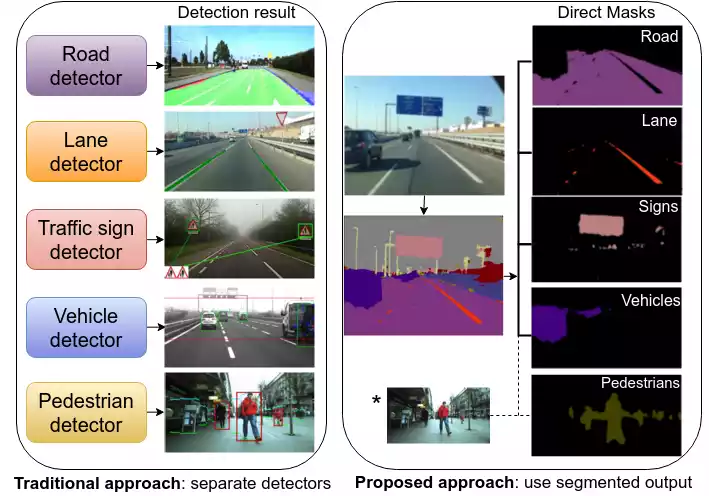
Ever wondered how self-driving cars “see” the road or how social media suggests photo tags? Image annotation is the secret sauce! It’s the process of adding labels to images, teaching machines to understand the visual world. This meticulous task is the foundation for many AI applications, from medical diagnosis to facial recognition. By labeling objects, scenes, and even individual pixels, we empower machines to learn and interpret the world around them. Want to know how image annotation unlocks the potential of AI? Dive deeper and discover its fascinating role in shaping the future!

Introduction to Image Annotation: The Language of Machines
In our increasingly digital world, images are everywhere. But for machines to truly understand these images, they need a helping hand – image annotation.
What is Image Annotation?
Imagine you’re showing a photo album to a young child. You might point and say, “See that fluffy white thing? That’s a cat.” Image annotation is similar, but for machines. It’s the process of adding labels or descriptions to digital images to convey their meaning.
Here’s how it works:
- Human Expertise: People, called annotators, meticulously examine images and add relevant information. This might involve drawing boxes around objects (bounding boxes), tracing their outlines with more complex shapes (polygons), or assigning labels to each pixel in the image (semantic segmentation).
- Structured Data: The annotations create a structured dataset, a kind of digital library with labeled images. This data becomes the training ground for machine learning models.
Why is Image Annotation Important?
Image annotation is the foundation for a variety of applications, particularly in the realm of Artificial Intelligence (AI) and machine learning (ML). Here’s why it’s crucial:
- Teaching Machines to See: Machines don’t inherently understand visual information. Image annotation provides the training data they need to learn and recognize objects, patterns, and relationships within images.
- Fuels Innovation: Annotated image datasets are the lifeblood of various AI applications. From facial recognition in smartphones to self-driving cars, image annotation plays a vital role in developing these technologies.
- Accuracy is Key: The quality of image annotation directly impacts the performance of AI models. Precise and well-labeled data leads to more accurate and reliable results.
Real-World Examples:
- Social Media: Image annotation helps platforms like Facebook identify people and objects in photos you upload, allowing for features like automatic tagging.
- Medical Diagnosis: Annotated medical scans can train AI models to detect abnormalities in X-rays or MRIs, aiding doctors in diagnosis.
- Autonomous Vehicles: Cars that drive themselves rely heavily on image annotation. Labeled images teach them to recognize pedestrians, traffic signs, and lane markings, enabling safe navigation.
Image annotation acts as a bridge between the human world of visual understanding and the machine learning realm. By carefully labeling images, we empower machines to “see” and interpret the world around them, paving the way for advancements in AI and various technological applications.
Image Annotation Process
The image annotation process involves a series of steps that transform raw images into a format machines can understand and learn from. Here’s a breakdown of the typical workflow:
Data Collection and Preparation:
- The process begins with gathering a collection of images relevant to the task at hand. This might involve taking photos, scraping data from the web, or using existing image datasets.
- Data quality is crucial. Images should be clear, well-lit, and representative of the variations you want the model to handle. Preprocessing steps like resizing or cropping images might be required for consistency.
Annotation Task Definition:
- Clearly define what information the annotations need to convey. This depends on the machine learning model’s purpose.
Common annotation tasks include:
- Bounding Boxes: Drawing rectangles around objects of interest in the image.
- Polygons: Using more complex shapes to outline irregularly shaped objects.
- Semantic Segmentation: Assigning labels to each pixel in the image, indicating the object it belongs to (e.g., road, car, pedestrian).
- Image Classification: Labeling the entire image with a single category (e.g., cat, dog, landscape).
Tool Selection and Annotation Interface:
- Choose an image annotation tool that aligns with your project’s needs and technical expertise. Tools offer functionalities for specific annotation tasks and might have features like hotkeys or automation to streamline the process.
- The annotation interface typically displays images one at a time, along with tools for drawing shapes, assigning labels, and navigating the dataset.
Image Annotation:
- This is where the magic happens! Trained annotators meticulously examine each image and apply the defined annotations using the chosen tool.
- Accuracy and consistency are paramount. Annotators follow defined guidelines and quality control measures might be implemented to ensure data integrity.
Data Validation and Refinement:
- Once annotated, the data undergoes a validation process. A second annotator might review the labels for errors or inconsistencies.
- Disagreements between annotators might require adjudication or retraining to ensure consistent labeling.
Data Export and Use:
- The final, validated dataset is exported in a format compatible with your machine learning model. Common formats include CSV, JSON, or COCO.
- This labeled data is then used to train the model. The model learns to recognize patterns and relationships within the labeled data, enabling it to perform the desired task (object detection, image classification, etc.) on new, unseen images.
Additional Considerations:
- Project Scale: For large datasets, consider using semi-automatic annotation or distributed annotation tasks among multiple workers.
- Active Learning: Some tools incorporate active learning techniques, where the model identifies which images require further annotation for optimal training efficiency.
By following a structured image annotation process, you can generate high-quality labeled data that forms the foundation for training powerful and accurate machine learning models.
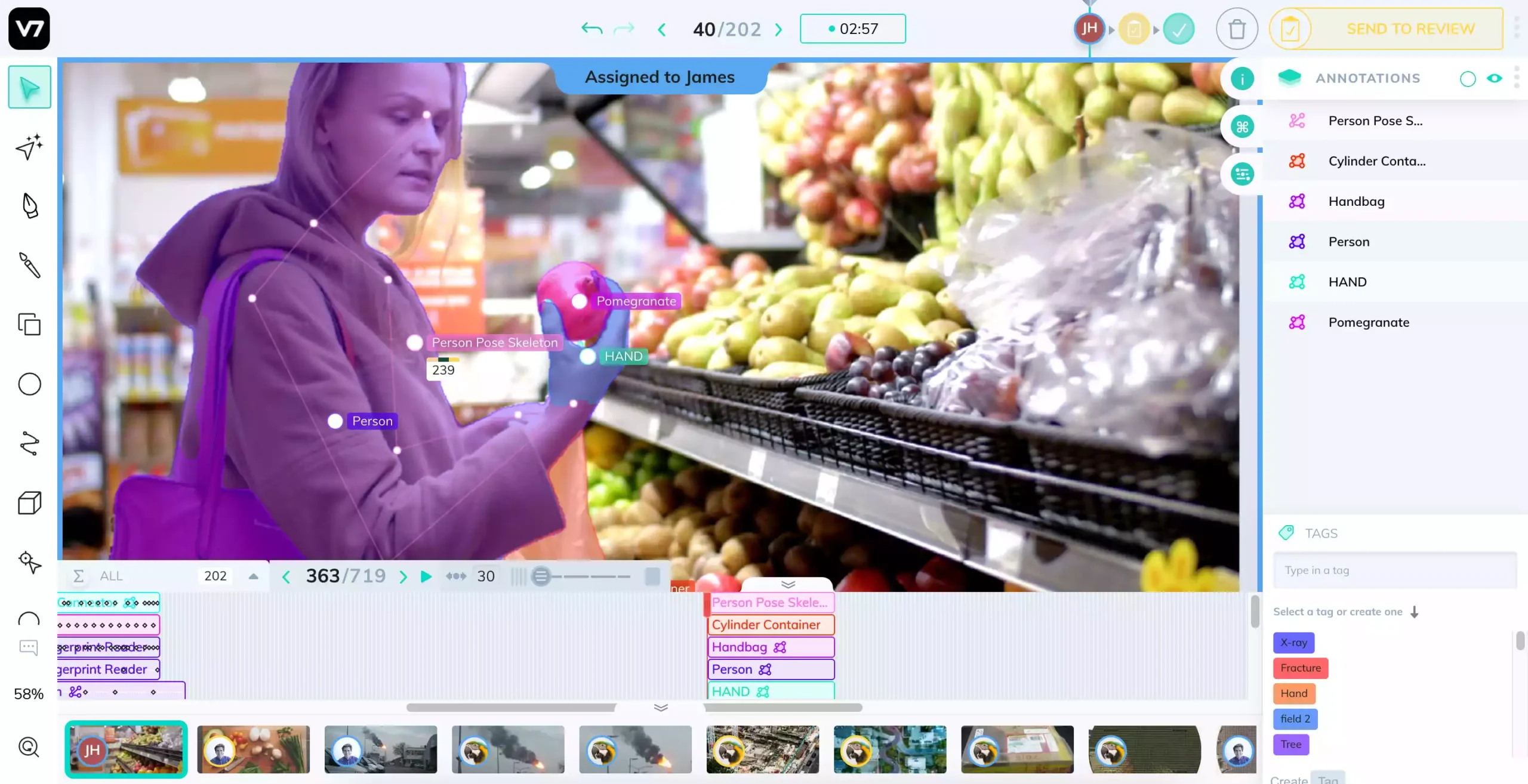
Types of Image Annotation
Image annotation plays a crucial role in computer vision tasks, enabling AI models to recognize and understand visual information. Here are some commonly used image annotation techniques:
Bounding Boxes: Guiding Machines to See
Bounding boxes are a fundamental concept in computer vision, particularly in tasks like object detection and localization. They act like a visual guide, helping machines understand what objects exist within an image and where they’re positioned.
Here’s a deeper dive into bounding boxes, along with examples and their role in training autonomous vehicles:
What are Bounding Boxes?
Imagine you’re a teacher guiding a child to identify objects in a picture. You might point and say, “See that brown rectangle? That’s a dog.” Bounding boxes function similarly in the digital world. They are rectangular frames drawn around objects of interest in an image. These frames convey two crucial pieces of information:
- Location: The box indicates the general area where the object resides in the image.
- Size: The box size provides an approximate idea of the object’s dimensions.
How are Bounding Boxes Used?
Bounding boxes are a powerful tool for training machine learning models, especially for object detection. Here’s how they work:
- Data Annotation: A large collection of images is used. Humans (annotators) meticulously draw bounding boxes around specific objects in each image. This process creates a labeled dataset.
- Model Training: The machine learning model is exposed to this labeled data. It analyzes the images and learns to recognize the patterns within the bounding boxes. This helps the model understand the relationship between the box and the object it represents.
- Object Detection: Once trained, the model can be used on new images. It can identify and localize objects by drawing conceptual bounding boxes around them, mimicking the training data.
Bounding Boxes for Self-Driving Cars
Autonomous vehicles rely heavily on robust object detection for safe navigation. Bounding boxes play a critical role in this process. Here’s how:
- Identifying Objects: Bounding boxes help the car’s perception system distinguish between various objects on the road, such as pedestrians (marked in a blue box in the image below), other vehicles (yellow boxes), and traffic lights (red box).

- Localization: By analyzing the position of the bounding box, the car can determine an object’s relative distance and location within the scene. This allows the car to make informed decisions about maneuvers like stopping, turning, or maintaining lane position.
In essence, bounding boxes provide a simplified yet effective way for machines to grasp the visual world. By learning from these labeled boxes, autonomous vehicles can develop a sense of their surroundings and navigate roads safely.
While bounding boxes are a powerful tool, they have limitations. They don’t capture the exact shape of an object, and they struggle with objects that are partially occluded (hidden behind something). As computer vision advances, more sophisticated techniques like polygon annotations (using multiple points to create a more defined shape) and 3D bounding boxes are being explored for a more comprehensive understanding of the visual world.
Polygons: Capturing the Nuances of Complex Shapes
Bounding boxes are great for simple objects, but what about those with intricate shapes or overlapping instances? That’s where polygons come in. Polygons offer a more precise way to annotate objects in computer vision tasks, particularly for autonomous vehicles.
What are Polygons?
- Imagine a child tracing the outline of a toy car with their finger. Polygons work similarly in the digital realm. They are closed shapes formed by connecting a series of straight lines (segments) around an object. Unlike bounding boxes, polygons can have any number of sides, allowing them to capture the true form of an object more accurately.
Benefits of Polygons:
- Precise Annotations: Polygons excel at outlining objects with irregular shapes, like pedestrians with backpacks or bicycles. This precision is crucial for tasks requiring detailed information about an object’s form.
- Handling Overlap: When objects partially obscure one another (occlusion), bounding boxes can become ambiguous. Polygons can define the exact boundaries of each object, even in overlapping scenarios.
Polygons in Autonomous Vehicles:
Precise object recognition is vital for autonomous vehicles. Here’s how polygons can enhance their perception systems:
- Lane Markings: Unlike the straight lines of a bounding box, polygons can meticulously trace the curves and bends of lane markings on the road, providing a more accurate representation for path planning (see image below).

- Traffic Cones: Polygons can precisely define the triangular shape of traffic cones, even when they’re tilted or partially obscured by other objects. This ensures the car can correctly identify and react to these important road signals.
Polygons offer a significant advantage over bounding boxes, but they also have limitations. Annotating complex objects with many vertices can be time-consuming. Additionally, for tasks requiring 3D information, like judging object distance, polygons alone might not be sufficient.
As computer vision evolves, so do the annotation techniques. Techniques like Bézier curves (using smooth curves instead of straight lines) and even 3D polygon meshes are being explored for even more accurate object representation in the digital world.
Semantic Segmentation: Seeing the Bigger Picture in Self-Driving Cars
Bounding boxes and polygons excel at pinpointing specific objects, but what if we want to understand the entire scene in an image? This is where semantic segmentation comes into play. It delves deeper, giving machines the ability to not just detect objects but also comprehend their surroundings.
What is Semantic Segmentation?
- Imagine a child excitedly pointing at a picture and saying, “Look, there’s a car on the road!” Semantic segmentation takes this a step further. It assigns a specific label (like “car” or “road”) to every single pixel in an image. This creates a kind of digital map, revealing the identity of each image region.
How Does it Work?
- Deep Learning Models: Complex algorithms called deep learning models are trained on massive datasets of labeled images. Each pixel is assigned a label based on its color, texture, and spatial relationship with other pixels.
- Pixel-Wise Labeling: Unlike bounding boxes that focus on objects, semantic segmentation labels every single pixel. This intricate labeling empowers the model to grasp the finer details of the scene.
Semantic Segmentation for Autonomous Vehicles:
For self-driving cars, a nuanced understanding of the environment is paramount. Here’s how semantic segmentation aids their perception systems:
- Scene Understanding: By analyzing the labeled image, the car can not only detect objects (vehicles, pedestrians) but also comprehend their context. It can distinguish between a “drivable road” and a “sidewalk,” or a “parked car” versus a “moving car.”
- Advanced Perception: Semantic segmentation provides a richer understanding of the scene, allowing the car to make informed decisions. It can anticipate potential hazards (pedestrians crossing the road) and plan maneuvers accordingly.
Semantic segmentation offers a powerful tool for scene comprehension, but it’s not without limitations. These models can be computationally expensive to run, and they might struggle with rare or unseen scenarios.
Researchers are actively exploring ways to improve segmentation techniques. Areas of focus include incorporating depth information (from LiDAR sensors) and real-time processing for faster decision-making in autonomous vehicles.
Image Classification: Simplifying the Scene
Image classification is a fundamental task in computer vision. It involves assigning a single category label to an entire image, essentially telling the machine “what” the image depicts. This seemingly simple task lays the groundwork for various applications, and here’s a deeper look with examples:
The Process:
Imagine sorting photos into an album. You might glance at an image and say, “This is a picture of a cat.” Image classification follows a similar approach for machines:
- Feature Extraction: The image is analyzed to extract key characteristics like color, texture, and shapes. These features act as clues that help the machine understand the image content.
- Classification Model: A machine learning model, trained on a massive dataset of labeled images, takes these features as input. The model has learned to associate specific feature combinations with different categories.
- Category Prediction: Based on the extracted features, the model predicts the most likely category label for the image. For example, it might predict “cat” with a high confidence score.
Examples and Applications:
Image classification has a wide range of applications, here are a few:
- Social Media: Platforms like Facebook use image classification to automatically suggest tags for photos you upload. Analyzing the image content, the model might recognize a scene and suggest “beach” or identify objects like “dog” or “person” for tagging.
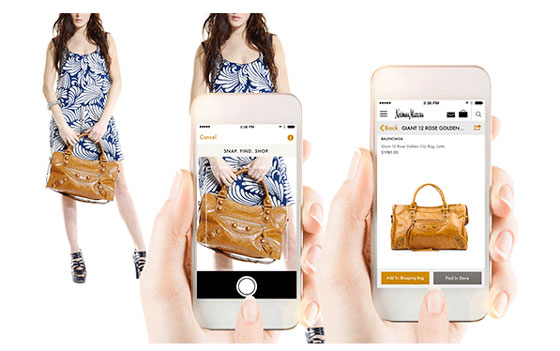
- E-commerce: Online stores use image classification to categorize product images. Uploading an image of a shoe, the model might classify it as “sneakers” or “dress shoes,” aiding in product organization and search functionalities.
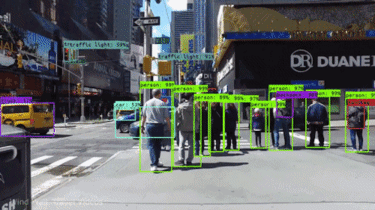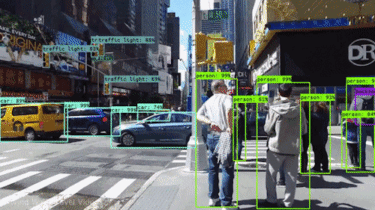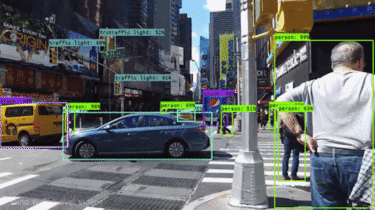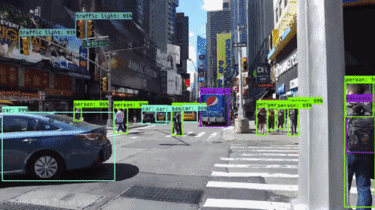
- Self-Driving Cars: While more complex tasks like object detection are involved, image classification can play a supporting role. For instance, the car’s system might classify an image as a “traffic light scene” to trigger further analysis for identifying specific light colors (red, yellow, green).
Benefits and Limitations:
- Simplicity: Image classification offers a straightforward approach for labeling images. It’s computationally less expensive compared to more complex tasks like object detection.
- Limited Detail: The single category label doesn’t capture the finer details within an image. For instance, classifying an image as “landscape” doesn’t reveal the presence of animals or specific objects within the scene.
While image classification is a powerful tool, it has limitations. As computer vision advances, techniques like object detection (identifying and locating multiple objects within an image) and semantic segmentation (assigning labels to each pixel) are gaining traction for a more comprehensive understanding of visual data.
Techniques for Image Annotation: A Spectrum of Approaches
Image annotation, as we discussed, is the process of adding labels or descriptions to images to train AI models. But how exactly do we achieve this labeling? Different techniques offer varying levels of human involvement and automation. Let’s delve into three main approaches:
1. Manual Annotation: The Gold Standard
Manual annotation remains the most common and reliable technique. Here’s how it works:
- Human Expertise: Trained annotators meticulously examine each image and apply labels using specialized annotation tools. This might involve drawing bounding boxes, tracing object outlines with polygons, or assigning labels to every pixel (semantic segmentation).
- High Accuracy: Since humans perform the labeling, this method offers the highest level of accuracy and control. Annotators can capture intricate details and handle complex scenarios that might challenge automation.
- Time-Consuming: However, manual annotation is a slow and labor-intensive process, especially for large datasets. The sheer volume of images can make it expensive and time-consuming.
2. Semi-Automatic Annotation: A Balancing Act
Striking a balance between human expertise and automation, semi-automatic annotation offers a faster approach:
- Leveraging Automation: Machine learning models pre-trained on existing datasets can suggest labels or pre-populate bounding boxes for annotators. This reduces the time spent on repetitive tasks.
- Human Refinement: Annotators then review and refine the automated suggestions, ensuring accuracy and correcting any errors made by the model.
- Increased Efficiency: By combining human oversight with machine assistance, semi-automatic annotation offers a faster and more cost-effective approach compared to purely manual methods.
3. Automatic Annotation: The Quest for Efficiency
The holy grail of image annotation is complete automation. Here’s the idea:
- Automated Labeling: Machine learning models, trained on vast amounts of labeled data, would automatically assign labels to new images without human intervention.
- Speed and Efficiency: This approach promises significant speed and cost benefits, ideal for processing massive datasets.
- Challenges Remain: However, automatic annotation technology is still under development. Accuracy can be lower compared to manual methods, especially for complex images or new visual concepts.
Choosing the Right Technique
The choice of technique depends on several factors:
- Project Requirements: The level of accuracy needed, project budget, and dataset size all play a role.
- Image Complexity: For simpler images, automatic or semi-automatic methods might suffice. Complex images might require manual annotation for higher accuracy.
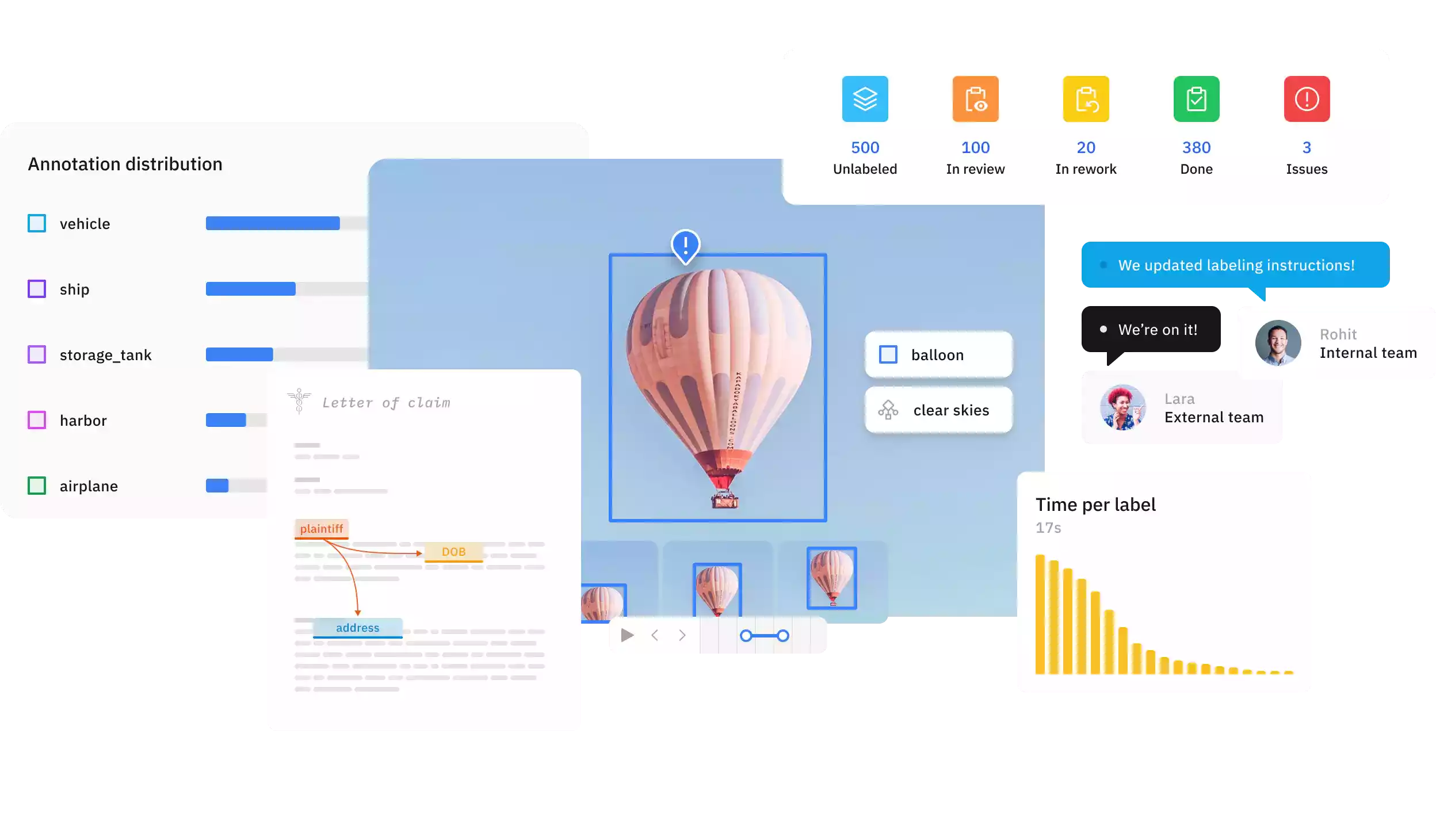
Image Annotation Tool
Image annotation is a crucial part of training machine learning models, especially in computer vision tasks. It involves adding labels or descriptions to images to convey their meaning to machines. These annotations are then used to train models to recognize objects, patterns, and relationships within images.
There are various image annotation tools available, each with its own strengths and weaknesses. Here’s a breakdown of some popular options:
Free, Open-Source Tools:
- VOTT (Visual Object Tagging Tool): Developed by Microsoft, VOTT is a user-friendly tool that supports various annotation tasks like object detection, image segmentation, and image classification. It offers an intuitive interface and the ability to export data in different formats compatible with popular machine learning frameworks.

- LabelImg: This lightweight tool is ideal for basic image annotation tasks like bounding boxes and polygons. It’s simple to use and runs on most operating systems.
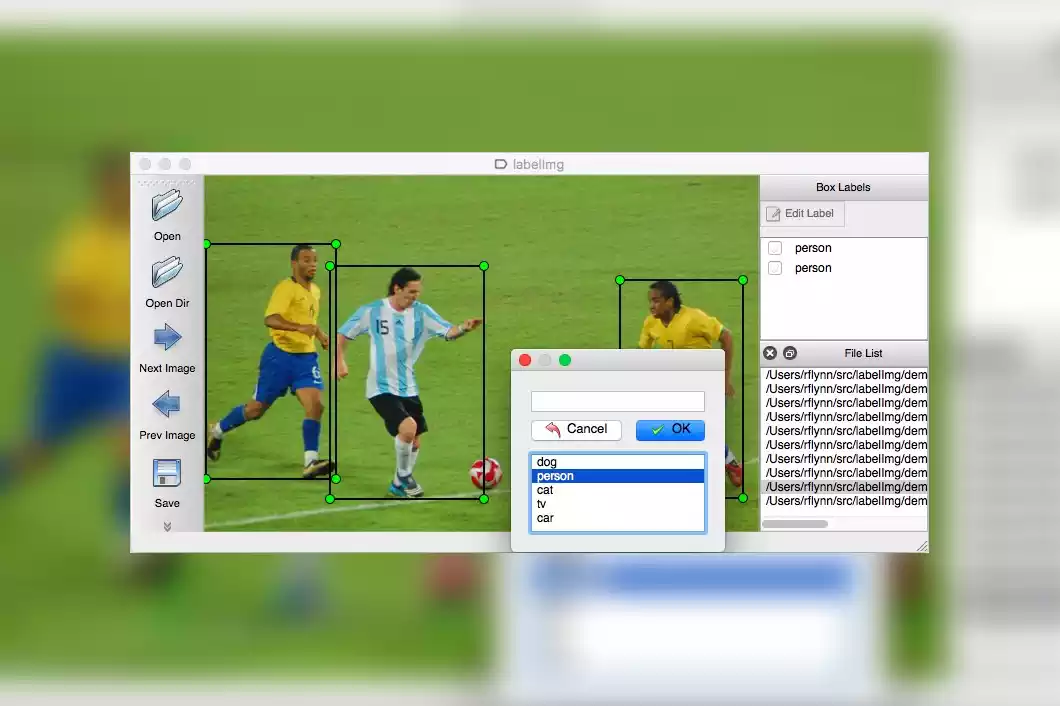
- CVAT (Computer Vision Annotation Tool): A powerful open-source platform offering features for image and video annotation. CVAT supports various labeling tasks, collaboration tools, and dataset management functionalities.

Commercial Annotation Tools:
- Labelbox: This cloud-based platform offers a comprehensive suite of annotation tools, including advanced features for image, video, and text data. Labelbox provides a user-friendly interface, collaboration tools, and quality control measures to ensure data accuracy.
- Scale AI: This company offers a platform with various tools for data labeling, including image annotation. Scale AI caters to enterprises with features for managing large datasets, automating workflows, and integrating with machine learning models.
- SuperAnnotate: This platform focuses on streamlining the annotation process for teams. SuperAnnotate provides tools for image, video, and text annotation, along with features for collaboration, quality control, and active learning to improve model performance iteratively.

Choosing the Right Tool
The ideal annotation tool depends on your specific needs. Here are some factors to consider:
- Project Requirements: Consider the type of annotation task (bounding boxes, polygons, semantic segmentation), project complexity, and desired level of accuracy.
- Budget: Free, open-source tools are a good option for smaller projects. Commercial platforms might offer more advanced features but come with subscription costs.
- Team Size: Collaboration features become important for projects involving multiple annotators.
Technical Expertise: Some tools require more technical knowledge to set up and use, while others offer user-friendly interfaces.
By considering these factors, you can select the image annotation tool that best suits your project’s requirements and helps you efficiently generate high-quality labeled data for your machine learning models.
Image Annotation Applications
Image annotation has become a crucial step in developing various artificial intelligence (AI) applications, particularly those that rely on computer vision. Here’s a glimpse into some of the key areas where image annotation plays a vital role:
1. Self-Driving Cars:
- Task: Autonomous vehicles rely heavily on image annotation to “see” and understand their surroundings.
- Annotation Techniques: Techniques like bounding boxes are used to annotate objects like pedestrians, vehicles, and traffic signs. Semantic segmentation helps differentiate between lanes, sidewalks, and drivable areas.

- Impact: Accurate annotations train the car’s perception system to identify objects, predict their movements, and navigate roads safely.
2. Medical Imaging Analysis:
- Task: In healthcare, image annotation aids in developing AI models for medical diagnosis and analysis.
- Annotation Techniques: Medical professionals annotate X-rays, MRI scans, and other images to identify abnormalities, categorize diseases, and assist doctors in making informed decisions.
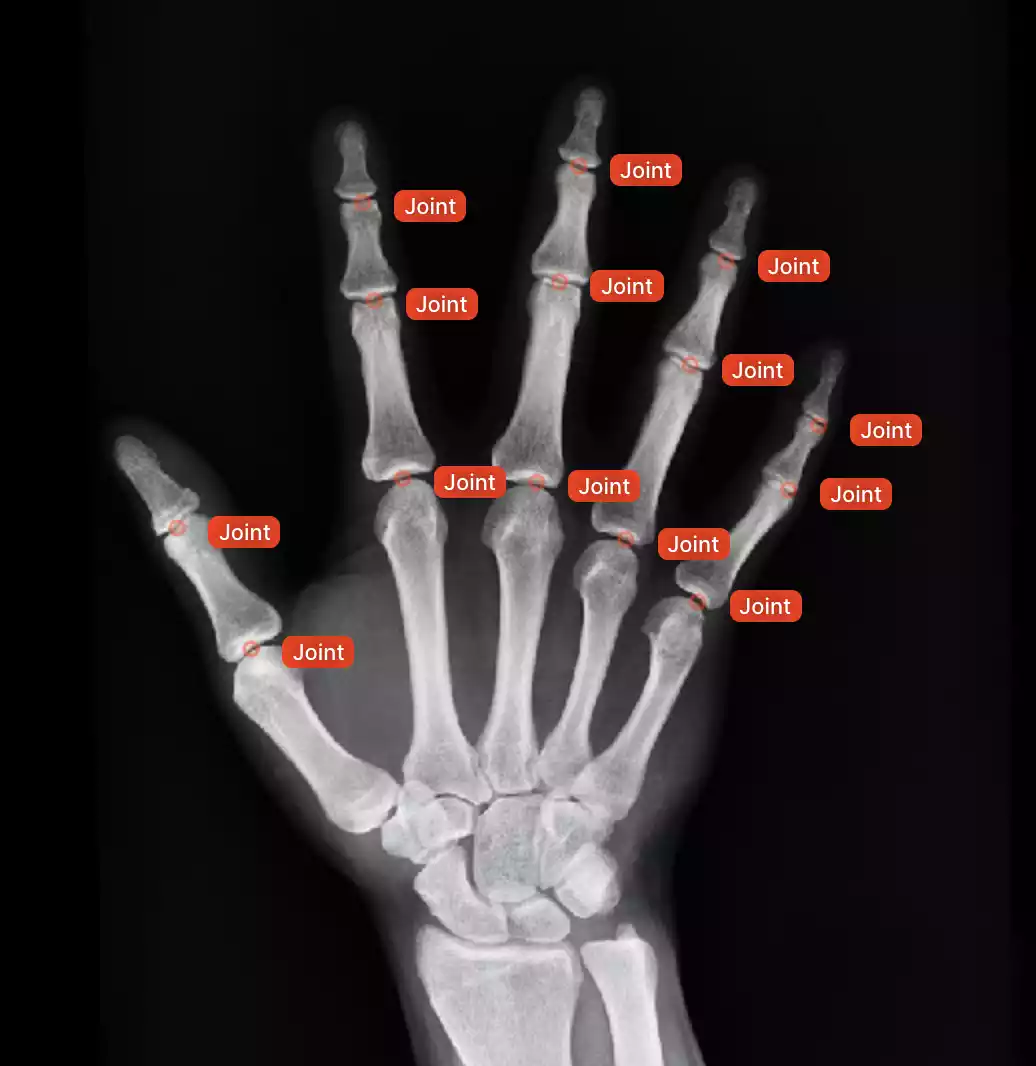
- Impact: Annotated medical images train AI models to detect tumors, diagnose illnesses, and personalize treatment plans, potentially leading to earlier diagnoses and improved patient outcomes.
3. Facial Recognition Technology:
- Task: Image annotation is essential for training facial recognition systems used in various applications.
- Annotation Techniques: Annotators meticulously label facial features like eyes, nose, and mouth in vast image datasets.

- Impact: Facial recognition technology finds applications in security systems, social media platforms (auto-tagging photos), and even law enforcement. However, ethical considerations regarding privacy and bias need to be addressed.
4. Content Moderation on Social Media:
- Task: Social media platforms leverage image annotation to train AI models for content moderation.
- Annotation Techniques: Images and videos are annotated to identify inappropriate content like hate speech, violence, or nudity.

- Impact: Automated content moderation helps maintain a safer online environment by filtering out harmful content. However, the accuracy of these models and potential biases require careful monitoring.
5. E-commerce and Retail:
- Task: Image annotation plays a role in enhancing online shopping experiences.
- Annotation Techniques: Product images are annotated with labels and attributes like clothing categories (dresses, shirts) or object types (furniture, electronics).

- Impact: Annotated product images enable better product search functionalities, personalized recommendations, and accurate image categorization for e-commerce platforms.
These are just a few examples, and the applications of image annotation are constantly expanding. As AI and computer vision evolve, image annotation will continue to be a critical tool for training intelligent machines to “see” and understand the world around them.
Conclusion
Image annotation has emerged as a foundational element in the realm of Artificial Intelligence (AI), particularly in computer vision. It acts as a bridge, translating visual information into a language machines can understand. By meticulously labeling images, we empower machines to “see” and interpret the world around them, paving the way for advancements in various technological applications.
We’ve explored the different techniques used for image annotation, from the detailed precision of manual labeling to the efficiency-driven approaches of semi-automatic and automatic methods. The choice of technique depends on factors like project requirements, image complexity, and desired accuracy.
The applications of image annotation are vast and constantly expanding. From the self-driving cars navigating our streets to the medical imaging analysis aiding healthcare professionals, image annotation plays a critical role in shaping the future.
However, challenges like data quality, bias, and privacy require careful consideration. Best practices like clear guidelines, annotator training, and data security measures are essential for ensuring high-quality labeled data that forms the backbone of powerful AI models.
Looking ahead, the future of image annotation is brimming with exciting possibilities. Advancements in automation, explainable AI, and privacy-preserving techniques hold the promise of even more efficient, reliable, and responsible methods for training the machines of tomorrow.
As the field of computer vision continues to evolve, image annotation will undoubtedly remain a vital tool in our quest to create intelligent machines that can not only see but also understand the visual world around them.
FAQs
Q. How do I choose the right annotation technique for my project?
A. Consider factors such as the complexity of the task, available resources, and desired level of annotation detail. Consulting with experts in image annotation can also help tailor the approach to your specific needs.
Q. What measures can I take to ensure the consistency of annotations across multiple annotators?
A. Providing clear annotation guidelines, conducting regular training sessions, and implementing quality control checks are effective ways to maintain consistency and accuracy in annotations.
Q. Are there any automated tools available for image annotation?
A. Yes, there are various software tools and platforms equipped with AI-powered annotation features that automate certain aspects of the annotation process. However, manual oversight and verification are often necessary to ensure annotation quality.
Q. How can image annotation benefit e-commerce businesses?
A. Image annotation can enhance product categorization, visual search capabilities, and personalized recommendations, leading to improved user experience and increased sales conversion rates in e-commerce platforms.
Q. What role does image annotation play in satellite imagery analysis?
A. In satellite imagery analysis, image annotation facilitates tasks such as land cover classification, urban planning, and environmental monitoring. Accurate annotations enable precise identification and monitoring of geographic features and changes over time.
How Text Annotation Tames the Wild World of Language | The Secret Weapon of AI in 2024
Data Annotation Jobs | Shaping the Future of Machine Learning in 21st Century
You have to wait 30 seconds.
Its like you read my mind You appear to know so much about this like you wrote the book in it or something I think that you can do with a few pics to drive the message home a little bit but other than that this is fantastic blog A great read Ill certainly be back.