In the field of AI, data annotation is crucial for training machine learning models to perform specific tasks accurately. Data annotation involves labeling and tagging data instances to provide valuable information for AI algorithms. There are different types of data annotation across various data types, including text annotation, image annotation, audio annotation, and video annotation.
In this chapter, we will explore text annotation. We will also provide relevant examples and case studies to enhance understanding. While we will primarily use the example of autonomous vehicles, it is important to note that the annotation processes discussed here apply to a wide range of industries and domains.

What is Text Annotation
Text annotation is the process of adding labels or metadata to raw text data. These labels provide additional information about the text’s content, structure, and meaning. Imagine it like highlighting and making notes on a document to improve your understanding. In NLP, text annotation serves the same purpose for machines.

Importance of Text Annotation in NLP
Text annotation is crucial for NLP because it allows machines to understand the nuances of human language. Here’s why it’s important:
- Provides Structure: Raw text data is unstructured. Annotation helps identify elements like sentences, paragraphs, and entities (people, places, organizations). This structure allows NLP models to analyze the text more effectively.
- Defines Meaning: Words can have multiple meanings depending on context. Annotation clarifies the intended meaning by labeling sentiment (positive, negative, neutral), parts of speech (nouns, verbs, etc.), and relationships between words.
- Trains NLP Models: Annotated text serves as training data for machine learning algorithms. The labels help the models learn to recognize patterns and features in the language, enabling them to perform tasks like sentiment analysis, information extraction, and machine translation.
In essence, text annotation bridges the gap between human understanding and machine interpretation of language. By providing the extra layer of meaning, annotated text data empowers NLP models to become more accurate and sophisticated.
Types of Text Annotation
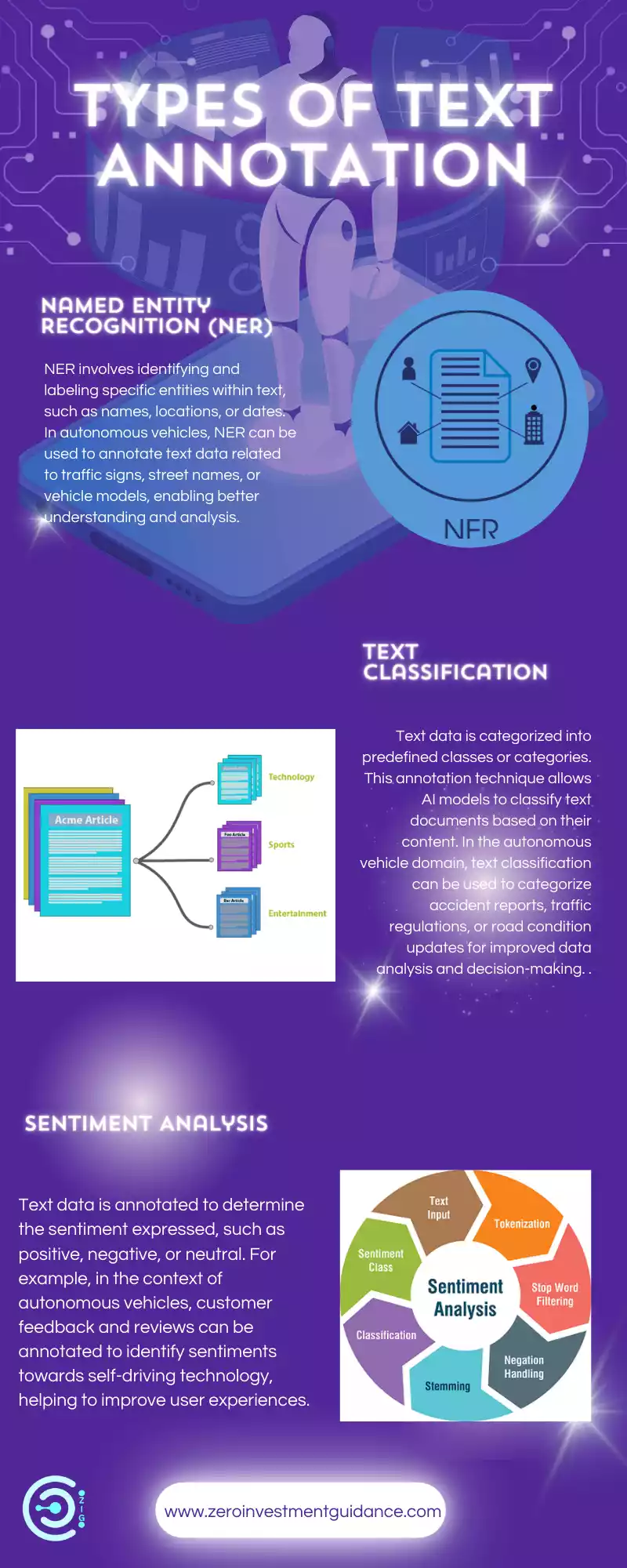
Text annotation comes in various flavors, each focusing on a specific aspect of the text. Here’s a breakdown of three common types:
Named Entity Recognition (NER):
NER involves identifying and labeling specific entities within text, such as names, locations, or dates. In autonomous vehicles, NER can be used to annotate text data related to traffic signs, street names, or vehicle models, enabling better understanding and analysis.
- Example: In the sentence “Barack Obama visited Paris in 2018,” NER would identify “Barack Obama” (Person), “Paris” (Location), and “2018” (Date).
- Importance: NER is crucial for tasks like information extraction, question answering, and building knowledge graphs.
Part-of-Speech (POS) Tagging/Text Classification:
Text data is categorized into predefined classes or categories. This annotation technique allows AI models to classify text documents based on their content. In the autonomous vehicle domain, text classification can categorize accident reports, traffic regulations, or road condition updates for improved data analysis and decision-making. Also, Assigns a grammatical label (part of speech) to each word in a sentence. These labels can be nouns, verbs, adjectives, adverbs, prepositions, etc.
- Example: In the sentence “The quick brown fox jumps over the lazy dog,” POS tagging would identify “The” (Determiner), “quick” (Adjective), “brown” (Adjective), etc.
- Importance: POS tagging helps understand the sentence structure and relationships between words. It’s vital for tasks like syntactic analysis, machine translation, and sentiment analysis.
Sentiment Analysis:
Text data is annotated to determine the sentiment expressed, such as positive, negative, or neutral. For example, in the context of autonomous vehicles, customer feedback and reviews can be annotated to identify sentiments towards self-driving technology, helping to improve user experiences. Focuses on identifying the emotional tone or opinion expressed in a piece of text. This can be a positive, negative, or neutral sentiment.
- Example: In the review “This movie was awful!”, sentiment analysis would classify the text as negative.
- Importance: Sentiment analysis is valuable for customer feedback analysis, monitoring social media, and gauging public opinion.
These are just three examples, and there are many other types of text annotation used in NLP, each with its purpose. The specific type of annotation used depends on the desired outcome of the NLP task.
Tools and Techniques for Text Annotation

There are several approaches to text annotation, each with its advantages and limitations. Here’s a look at three main techniques:
Manual Annotation:
The most traditional method, is where human annotators read and label the text data according to predefined guidelines.
- Advantages: Ensures high-quality and accurate annotations, especially for complex tasks.
- Disadvantages: Time-consuming, expensive for large datasets, and prone to human error due to subjectivity.
Rule-based Annotation:
Leverages predefined rules and patterns to automate some aspects of the annotation process. These rules can be based on dictionaries, regular expressions, or other heuristics.
- Advantages: Faster and less expensive than manual annotation, reduces human error for repetitive tasks.
- Disadvantages: Requires significant upfront effort to define and maintain the rules. May not handle complex or nuanced language effectively.
Machine Learning-based Annotation:
Utilizes machine learning models to assist with the annotation process. These models can be pre-trained on existing annotated data and then fine-tuned for specific tasks.
- Advantages: Can significantly speed up annotation for large datasets. Models can learn and adapt to improve accuracy over time.
- Disadvantages: Relies on the quality of the training data. It may require expertise in machine learning to implement and maintain effectively.
Choosing the Right Technique:
The best approach for text annotation depends on several factors, including:
- Project size and budget: Manual annotation is suitable for small projects but expensive for large ones.
- Data complexity: Complex tasks might require manual oversight, while simpler tasks can benefit from automation.
- Desired accuracy: Manual annotation is preferred for high-accuracy needs, while automated approaches can be used for faster yet less precise results.
Many projects might combine these techniques. For instance, machine learning can pre-annotate data, then human experts can review and refine the labels for maximum accuracy.
Challenges in Text Annotation
While text annotation is powerful, it’s not without its hurdles. Here are two major challenges to consider:
Ambiguity and Subjectivity:
- Language is inherently ambiguous. The same word can have multiple meanings depending on context. For example, “bat” can refer to a flying mammal or a baseball tool.
- Similarly, subjectivity can creep in, especially for tasks like sentiment analysis. “This movie was good” could be a positive or lukewarm review depending on the viewer’s expectations.
These factors can lead to disagreements between annotators, impacting the consistency and quality of the annotations.
Consistency and Quality Control:
- Maintaining consistency in annotations is crucial for reliable NLP models. However, annotators might have slightly different interpretations of the guidelines, leading to inconsistencies.
- Quality control measures are essential to ensure the accuracy and reliability of the annotated data. This might involve inter-annotator agreement checks, where multiple annotators label the same data, and discrepancies are resolved.
Here are some ways to address these challenges:
- Develop clear and comprehensive annotation guidelines: Detailed instructions with examples can minimize ambiguity and ensure consistent labeling.
- Use glossaries and style guides: Provide a reference for specific terms and formatting to promote consistency.
- Employ double annotation: Have multiple annotators label the same data to identify and rectify inconsistencies.
- Utilize adjudication processes: Establish a system to resolve disagreements between annotators and ensure final labels are accurate.
- Leverage active learning: Train machine learning models to identify uncertain cases and prioritize those for human annotation, focusing annotator effort where it matters most.
By acknowledging these challenges and implementing appropriate solutions, we can ensure high-quality text annotations that empower NLP models to perform at their best.
Applications of Text Annotation
Text annotation finds applications across various fields, fueling the advancements in NLP. Here’s how it benefits three specific areas:
Machine Translation:
- Accurate translation hinges on understanding the nuances of language.
- Text annotation, particularly NER (identifying entities like locations and names) and POS tagging (understanding grammatical structure), helps machine translation systems produce more accurate and natural-sounding translations.
- By annotating parallel corpora (text in two languages with corresponding meaning), machine learning models learn the relationships between words and phrases in different languages, leading to improved translation quality.
Information Retrieval:
- Text annotation plays a crucial role in information retrieval systems, which help users find relevant information from vast amounts of text data.
- Techniques like keyword extraction and topic modeling (identifying themes in text) facilitate effective indexing and search.
- For instance, annotating documents with relevant topics allows search engines to understand the content better and return more accurate results for user queries.
Question Answering Systems:
- Question answering (QA) systems aim to provide precise answers to user questions posed in natural language.
- Text annotation helps train these systems by categorizing information within text data.
- Techniques, like named entity recognition and relationship extraction (identifying connections between entities), enable QA systems to comprehend the context of a question and pinpoint the most relevant answer within annotated documents.
These are just a few examples, and text annotation contributes to various other NLP applications, including:
- Sentiment Analysis: As discussed earlier, sentiment analysis benefits from text annotation to understand the emotional tone of text data.
- Chatbots and Virtual Assistants: Annotating training data with conversational patterns improves the ability of chatbots and virtual assistants to understand and respond to user queries more naturally.
- Text Summarization: Text annotation helps identify key points and entities within a document, facilitating the creation of concise and informative summaries.
By providing the foundation for understanding human language, text annotation is a cornerstone of advancements in NLP and artificial intelligence.
Future Trends in Text Annotation

The future of text annotation is brimming with exciting possibilities that aim to address current limitations and enhance the overall process. Here are some trends to watch out for:
Advanced Annotation Techniques:
- Focus on Contextual Understanding: Moving beyond basic labeling, future techniques will delve deeper into capturing the contextual meaning of language. Annotation schemes might incorporate sarcasm detection, figurative language recognition, and sentiment analysis with finer gradations (e.g., beyond just positive, negative, and neutral).
- Crowd-Sourcing with Expertise: While crowdsourcing can accelerate annotation, ensuring quality remains a concern. The future might see a blend of human expertise and crowd-sourced labeling, where tasks are distributed based on annotator skill sets.
Integration with Deep Learning Models:
- Active Learning and Annotation Suggestion: Machine learning models can play a more prominent role in suggesting which data points require human annotation. This “active learning” approach prioritizes annotator effort on the most impactful data for model training, leading to increased efficiency.
- Generative Pre-annotation: Large language models (LLMs) themselves might be utilized to pre-annotate data. These models, trained on massive amounts of text data, can propose initial labels that human experts can then refine. This can significantly speed up the annotation process for large datasets.
These advancements, along with continuous efforts to improve consistency and quality control, promise to make text annotation a more robust and efficient process. This will fuel the development of even more sophisticated NLP models, leading to breakthroughs in various fields that rely on human language understanding.
Case Studies: Text Annotation in Action

Here are two case studies showcasing how text annotation is applied in different NLP tasks:
Case Study 1: Improving Social Media Sentiment Analysis
Challenge:
- A social media company wants to analyze user sentiment on their platform to understand user perception of their new product launch. However, social media text is often informal, and sarcastic, and uses slang, making automated sentiment analysis challenging.
Solution:
The company employs a combination of text annotation techniques:
- Sentiment lexicon development: Annotators create a list of words and phrases commonly used to express positive, negative, and neutral sentiments, considering informal language and slang specific to the platform.
- Sarcasm detection: Annotators label a sample of social media posts as sarcastic or non-sarcastic, training a machine learning model to identify sarcasm in future posts.
Outcome:
- By annotating training data with sentiment nuances and sarcasm indicators, the company’s NLP model can more accurately analyze user sentiment, providing valuable insights into user perception of the product launch.
Case Study 2: Enhancing Medical Information Retrieval
Challenge:
- A healthcare organization wants to develop a system that allows doctors to quickly retrieve relevant medical information from a vast library of research papers. Traditional keyword searches might miss relevant papers due to the technical language used in medical research.
Solution:
The organization implements text annotation for the research papers:
- Named Entity Recognition (NER): Annotators identify and classify medical entities like diseases, drugs, and genes within the papers.
- Relationship annotation: Annotators define relationships between these entities, such as a drug treating a specific disease.
Outcome:
- With NER and relationship annotations, the information retrieval system can understand the meaning and context of medical terms. Doctors can then search for information based on entities and relationships, leading to more efficient and accurate retrieval of relevant research papers.
These case studies illustrate how text annotation can be tailored to address specific NLP challenges. By providing the foundation for machines to understand the intricacies of language, text annotation empowers various applications to improve user experience and achieve desired outcomes.
Conclusion
Text annotation has emerged as a critical force in the realm of Natural Language Processing (NLP). By enriching raw text data with meaning and structure, annotation empowers machines to grasp the intricacies of human language. We’ve explored various types of annotation, from identifying entities and parts of speech to gauging sentiment.
The tools and techniques employed range from manual labeling to leveraging machine learning models, each with its strengths and considerations. While challenges like ambiguity and ensuring consistency persist, advancements in annotation techniques and the integration of deep learning models offer promising solutions.
As text annotation continues to evolve, it will undoubtedly pave the way for even more remarkable NLP applications, shaping the future of human-computer interaction.
FAQs
Q. What is text annotation?
A. Text annotation is the process of adding labels or metadata to raw text data. These labels provide additional information about the text’s content, structure, and meaning. It’s like highlighting and making notes on a document to improve understanding but for machines.
Q. Why is text annotation important in NLP?
A. Text annotation is crucial for NLP because it allows machines to understand the nuances of human language. By providing labels and structure, machines can learn the meaning of words, identify relationships between them, and grasp the overall sentiment of a text. This forms the foundation for various NLP tasks like machine translation, information retrieval, and question answering.
Q. What are the different types of text annotation?
A. There are many types of text annotation, each focusing on a specific aspect of the text. Here are three common types:
Q. Named Entity Recognition (NER): Identifies and classifies named entities like people, places, organizations, dates, etc.
A. Part-of-Speech (POS) Tagging: Assigns a grammatical label (noun, verb, adjective, etc.) to each word in a sentence.
Sentiment Analysis: Identifies the emotional tone of a text (positive, negative, or neutral).
Q. What are the common tools and techniques used for text annotation?
A. Text annotation can be done manually, with human annotators labeling the data. Rule-based annotation uses predefined rules and patterns to automate some aspects. Machine learning-based annotation leverages machine learning models to assist with the process. The best approach depends on project size, data complexity, and desired accuracy.
Q. What are the challenges in text annotation?
A. Ambiguity and subjectivity in language can lead to disagreements between annotators. Maintaining consistency and quality control is crucial for reliable NLP models. Techniques like clear guidelines, double annotation, and adjudication processes help address these challenges.
Q. What are some applications of text annotation?
A. Text annotation benefits various NLP applications:
- Machine translation: Improves accuracy by understanding entities and sentence structure.
- Information retrieval: Enables effective search by categorizing information within text data.
- Question answering systems: Helps identify the most relevant answer to a user’s question by understanding the context of the text.
- Sentiment analysis: Provides the foundation for understanding the emotional tone of text data.
- Chatbots and virtual assistants: Improves their ability to understand and respond to natural language queries.
- Text summarization: Helps identify key points within a document for concise summaries.
Q. What are the future trends in text annotation?
A. Future trends focus on advanced techniques like capturing contextual meaning and integrating deep learning models. This might involve:
- Crowd-sourcing with expertise: Combining human expertise with crowd-sourced labeling for better quality control.
- Active learning: Machine learning models suggest the reading understanding which data points need human annotation for efficient training.
- Generative pre-annotation: Large language models proposing initial labels to be refined by human experts, speeding up annotation.
By overcoming challenges and embracing advancements, text annotation will continue to empower NLP models and unlock new possibilities in human-computer interaction.
Understanding Data Annotation | Enhancing Machine Learning with Quality Data in 21st Century
Data Annotation Jobs | Shaping the Future of Machine Learning in the 21st Century
You have to wait 30 seconds.